Introducción
En el largo viaje de nuestra civilización a través de su historia, desolados por la
incapacidad de explicar su entorno, nuestros antepasados construyeron todo tipo de
armazones de carácter intelectual para llenar sus carencias cognitivas. En ocasiones
estas se constituían a partir de la observación de la realidad como conjuntos de creencias
o dogmas, sin capacidad predictiva ni confirmación fáctica. En otras, a partir del
acopio de nociones construidas mediante la observación y la integración estructurada
y sistemática de evidencias empíricas, trayendo a la luz al más sofisticado producto
del intelecto humano: el conocimiento científico. El desarrollo de este último no
ha sido un proceso terso, exento de convulsiones. Al decir de T. Kuhn [1] la acumulación de saberes científicos se produce a través de sucesivas sacudidas
intelectuales en las cuales un viejo paradigma es desechado por la comunidad y otro
nuevo es aceptado.
Las diferentes disciplinas científicas reprodujeron el inevitable proceso de división
social del trabajo, generando una especialización del conocimiento en diferentes ramas.
La más basta clasificación, que tiene sus orígenes en la Ilustración, fue entre filosofía
natural cuyo objeto de estudio era la naturaleza accesible en aquellos tiempos, y
filosofía moral1 que tenía como centro de atención el estudio de las acciones humanas y aquellos aspectos
de la misma relacionados con el bien, la virtud, el deber y la felicidad [2]. A pesar de la diferencia entre sus objetos de estudio, estas dos grandes áreas de
pensamiento han seguido una sólida interacción, compartiendo metáforas metodológicas
a lo largo de siglos [5]. Thomas Hobbes sostuvo que el trabajo de Euclides Los Elementos con su método axiomático
era un marco metodológico adecuado para el estudio de fenómenos sociales inyectando
en su Leviatán esta aspiración axiomática. J. C. Maxwell, después de leer la obra
de H. Buckle Historia de la Civilización en Inglaterra, le comentó en una carta a
su amigo L. Campbell:
La más pequeña porción de materia que sometemos a experimento consiste de millones
de moléculas, a ninguna de las cuales podemos acceder individualmente […] por tanto,
estamos obligados a abandonar el método histórico estricto2 y adoptar métodos estadísticos para tratar con estos grandes grupos de moléculas
[…] en el estudio de las relaciones entre algunas magnitudes, nos encontramos con
un nuevo tipo de regularidad, la regularidad de los promedios, la cual es suficiente
para todos los propósitos prácticos.
Más adelante, en una conferencia dictada en la Universidad de Cambridge el 11 de febrero
de 1873, el científico escocés afirmaba:
El método estadístico de investigar cuestiones sociales tiene a Laplace como su mejor
científico y a Buckle como su más popular expositor. Las personas están agrupadas
de acuerdo con alguna característica […] Este es el material básico del cual los estadísticos
deducen los teoremas generales de la sociología […] Ahora, si la teoría molecular
de la constitución de los cuerpos es verdad, todo nuestro conocimiento de la materia
es de tipo estadístico también […] En consecuencia, aquellas uniformidades que observamos
en nuestros experimentos con cantidades de materia que contiene millones de millones
de moléculas son uniformidades del mismo tipo que aquellas explicadas por Laplace
y Buckle y que surgen de la multitud de casos cada uno de los cuales no tiene relación
con los otros.
L. Boltzmann, otro de los padres fundadores de la mecánica estadística estaba también
muy influido por los resultados en las estadísticas sociales. En s utrabajo de 1872
puede leerse lo siguiente:3 “Las moléculas son como muchos individuos, tienen los más variados modos de movimiento
y las propiedades de los gases solo permanecen inalteradas porque el número de estas
moléculas que como promedio tienen un estado de movimiento dado, es constante. Alrededor
del año 1859, León Walras lee la obra de L. Poinsot Elementos de estática e inspirado por esta, en particular por el capítulo segundo de la misma y por otro
trabajo de Poinsot titulado Teoría general del equilibrio y el movimiento de los sistemas, desarrolló el marco teórico para su teoría del equilibrio general económico, que
compartió con H. Poincaré a través de un intenso intercambio epistolar.4 Los anteriores ejemplos nos muestran que el intercambio de metáforas metodológicas
ha sido esencial en algunos de los más notables descubrimientos de nuestra civilización.
Otro detonante de los grandes cambios que ocurren en las diferentes disciplinas científicas
son los nacientes instrumentos de investigación. Tal es, por ejemplo, el caso del
microscopio. Aristóteles, considerado como uno de los padres de la biología, afirmaba
que los seres vivos estaban formados por partes pequeñas que componían un todo, pero
no estaba en condiciones de describir esas pequeñas partes por la falta de un instrumento
adecuado. La teoría celular publicada por M. Schleiden y M. Schwann en 1838, basada
obviamente en la observación microscópica hizo pasar a la botánica de la ciencia meramente
clasificatoria que antes era a la emocionante especialidad científica que hoy es.
El telescopio de Galileo,5 tuvo igual influencia en la astronomía y las ciencias naturales. Su instrumento cambió
de manera radical la forma en que se percibía el sistema solar, poniendo en duda la
concepción ptolemaica y abriendo el camino a la visión heliocéntrica copernicana.
Desde este punto las cuidadosas observaciones hechas (con la ayuda del telescopio)
por T. Brahe y J. Kepler se convirtieron en la evidencia empírica que inició el paradigma
newtoniano.
Como veremos en este trabajo, las computadoras digitales se han convertido en una
suerte de telescopio de las ciencias sociales, a través de su trascendental capacidad
de almacenar y procesar cantidades impensables de datos. Necesitamos un cambio de
paradigma “galileano” en la investigación social, con una visión sistémica orientada
a la interacción entre los agentes sociales. Cuando se combinan las nuevas oportunidades
creadas por las tecnologías de la información y la comunicación, este cambio de paradigma
nos conducirá a una “sociedad digital” auto organizada que nos ayudará a superar (o
al menos mitigar) muchos problemas de larga data en nuestras comunidades como la inestabilidad
financiera, la delincuencia, conflictos, guerras u otras tragedias. De ese nuevo paradigma
se discute en estas páginas.
Los antecedentes
Las actuales ciencias sociales son una consecuencia de las transformaciones ocurridas
en las sociedades europeas a partir del siglo XVIII. La idea de que es válida una
reflexión sobre la naturaleza colectiva de los seres humanos, sobre las interrelaciones
de los miembros dentro de las diferentes comunidades y su posición al interior de
las estructuras sociales surge a la par de la aparición de nuevas formas de producción
basadas en el capitalismo industrial y las modificaciones en el plano de lo político
dadas por las ideas de la Revolución francesa. Las ciencias sociales, al decir de
I. Wallerstein,6 son una empresa del mundo moderno.
La voluntad de crear una “física social”, esto es, un conocimiento indiscutible de
la sociedad, de forma análoga a como se establece en la física, surgió con el positivismo
del siglo XIX a partir de la obra de A. Quetelet, en particular de su trabajo Sobre el hombre y el desarrollo de sus facultades o Ensayo de física social.7 Pero a diferencia de la física, los estudios sociales siempre han adolecido de una
endémica escasez de datos experimentales.
Este último estado de cosas ha estado cambiando sostenidamente desde finales de la
primera mitad del siglo anterior. Los esfuerzos de los criptoanalistas aliados para
romper los códigos alemanes durante la Segunda Guerra Mundial, los guiaron a la construcción
de las primeras máquinas computadoras. Si bien en las postrimerías de la Segunda Guerra
Mundial, W. Churchill ordenó destruir toda evidencia del esfuerzo criptoanalítico
de Bletchley Park,8 anulando todo el acervo intelectual desarrollado en esta área por los científicos
ingleses, en el mismo año de 1945, J. Eckert y J. Mauchl y de la Universidad de Pennsylvania,
completaron Eniac, una computadora con 18,000 bulbos capaz de ejecutar 5,000 operaciones
de punto flotante por segundo.
La irrupción de las computadoras digitales en nuestras vidas ha generado una colección
de cambios cada vez más drásticos en nuestras experiencias vitales. Así como el telescopio
nos abrió el universo y el microscopio nos reveló los secretos del microcosmos, las
computadoras comenzaron a abrir una excitante nueva ventana sobre la naturaleza de
la realidad ya desde la segunda mitad del siglo XX. A través de su capacidad para
procesar lo que es demasiado complejo para la mente humana sin ayuda, las computadoras
nos permitieron, por primera vez en la historia de la nuestra civilización, simular
nuestra realidad inmediata, en particular los fenómenos sociales, creando modelos
de sistemas completos como las grandes moléculas, los sistemas caóticos, los patrones
de evolución y el crecimiento poblacional.9
Pero sin duda la transformación más profunda y permanente sobre nuestra civilización
en la que las computadoras digitales han sido protagonistas es la infiltración de
la Internet en el tejido de nuestra cotidianidad.
Como es conocido, la historia de Internet comienza a principio de los años 1960, en
plena Guerra Fría, cuando la arpa, una agencia militar de EEUU, comenzó a financiar
proyectos de investigación en universidades para la creación de una red de computadoras.
La razón básica de este empeño militar era investigar las características óptimas
(en términos de redundancia) de las redes de computadoras que gobernaban los cohetes
intercontinentales con ojivas nucleares. Se temía que un ataque soviético pudiera
desmantelar completamente las defensas estratégicas. El primer intento exitoso de
construcción de una tal red fue hecho por L. Roberts del MIT y fue bautizada como
ARPANET por razones obvias. No obstante, el protocolo de transmisión de datos de la
misma, no poseía las propiedades idóneas para el funcionamiento sobre una arquitectura
abierta. Fueron R. Kahn y V. Cerf de la Universidad de Stanford quienes finalmente
crearon el TCP/IP que es el protocolo de transmisión de datos de la Internet actual.
Este último avance ocurre fuera de la égida de los militares.
Después de este primer impulso, el uso de las redes de computadoras languideció algunos
años. Aún a finales de la década de los 80, nadie sabía cómo obtener financiamiento
para seguir desarrollando una tecnología que tampoco nadie sabía cómo utilizar comercialmente.
El tema del acceso a los recursos se convirtió en un aspecto vital en el desarrollo
de las redes de computadoras en la comunidad académica y científica. La cantidad de
información crecía rápidamente, no así los recursos para almacenarla.
Un descubrimiento cambió el curso de los acontecimientos. De la misma forma en que
J. Gutenberg transformó la manera de producir libros, el lenguaje html revolucionó
la presentación de la información en la web. A partir de su creación, el concepto
de página web incorporaría textos, datos, imágenes y sonido de una manera integrada. Así, en el
año 1990, algunas empresas propusieron proyectos para participar en Internet. Este
proceso se aceleró hacia 1993. El modelo de negocios consistía en un inicio en promocionar
artículos o servicios comerciales en ciertas áreas de las páginas web. El precio de
esta promoción era proporcional al tamaño del espacio seleccionado y al número de
visitas que recibiera la página. Comenzó de esta forma una lucha por la popularidad
virtual. Los iniciadores de estos emprendimientos nunca imaginaron que los sitios
más exitosos no serían aquellos que brindaban noticias, modas, información financiera
o meteorológica o bien recetas de cocina. Los vencedores de esta batalla por la popularidad
serían aquellos sitios web que apostaron proveer algo bien intrínseco de la condición
humana: la comunicación interpersonal.
Así, surgieron las llamadas redes sociales. Su origen se remonta, por lo menos al
año 1995, cuando Randy Conrads crea el sitio web www.classmates.com. Con esta red social se pretendía que los usuarios pudieran recuperar o mantener
el contacto con sus antiguos compañeros de colegio, preparatoria, universidad, entre
otras.
En 2002 comienzan a aparecer sitios web promocionando los círculos de amigos en línea.
Este último término se empleaba para describir las relaciones en las comunidades virtuales,
y se hizo popular en 2003 con la llegada de sitios tales como MySpace o Xing. El tráfico
en estos sitios se hizo muy atractivo a los comerciantes. Debido a esto, grandes compañías
entraron en el terreno de las redes sociales en Internet. Sin embargo, como se sabe,
los sitios más exitosos tuvieron en general comienzos muy humildes.
En el año 2004, M. Zuckerberg fundó Facebook, un sitio de intercambio de información
personal, sin duda el más exitoso de la historia. Más adelante en 2005, Chad Hurley,
Steve Chen y Jawed Karim crearon www.youtube.com, un sitio para almacenar y compartir videos. Por último, en 2006, J. Dorsey creó
Twitter, un sitio que permite el envío de cortos mensajes a la comunidad de seguidores
del usuario. Al momento de escribir estas líneas, Twitter es una suerte de termómetro
digital de múltiples fenómenos sociales, permitiendo el monitoreo de la evolución
de elecciones presidenciales, los ataques terroristas, la difusión de epidemias y
las consecuencias de desastres naturales por solo mencionar algunos ejemplos. Queremos
hacer énfasis en un aspecto distintivo de estos sitios: en todos ellos se intercambia
información con el conjunto de amigos o seguidores de la persona que genera la cuenta.
El concepto de red es pues, intrínseco a los mismos.
Estas redes virtuales son los protagonistas básicos del proceso de creación de conocimiento
científico sobre las redes sociales, entendidas estas últimas como el conjunto de
individuos pertenecientes a una población conectados entre sí por algún criterio específico,
como puede ser amistad, interés sobre un tema en particular, nacionalidad, afición
a algún deporte, por mencionar algunos.
Por otra parte, la capacidad de almacenamiento de los dispositivos digitales ha permitido
la utilización de las grandes masas de datos que nuestra sociedad genera. Inmediatamente
que venimos al mundo, una parte cada vez mayor de los habitantes del planeta comienza
a generar un rastro digital. Se nos asigna un nombre que se registra en alguna base
de datos junto con nuestro peso, estatura y otras medidas de carácter fisiológico,
por primera vez. Algunos años más tarde o bien comenzamos a asistir a la escuela,
donde siguen registrándose datos acerca de nuestra persona o bien empezamos a formar
parte de la población laboral, dejando de igual forma un rastro digital. Participamos
en los censos organizados en el país que habitamos, recibimos un número de seguridad
social u otro tipo de identificador nacional y se crean registros médicos personales.
Nuestra propia actividad profesional registra aún más datos. Tal vez tenemos una cuenta
en Twitter, donde expresamos nuestras ideas acerca de múltiples temas y también, tal
vez, publiquemos fotos u otros materiales en algún sitio como Facebook o Instragram.
Revelamos nuestros intereses, deseos y preocupaciones en miles de búsquedas en Google.
Toda esa enorme masa de datos permite crear perfiles muy precisos de nosotros mismos.
La comunidad de esos perfiles ayuda a los especialistas en análisis de datos a crear
patrones de conducta. Por último, vale señalar que la precisión con la que esos patrones
nos describen es mucho mejor que la valoración que un psicoanalista puede hacer de
nosotros tras 2 años de estar tumbados en su diván.
Surgió así una nueva área del conocimiento llamada Big Data. No existe una definición
de la misma que cuente con la aceptación universal acerca de su contenido y objetos
de estudio.10 Se asume en general que son las técnicas cuantitativas necesarias para el estudio
de grandes masas de datos no estructurados que por su volumen deben utilizarse computadoras
digitales en su análisis. Conviene hacer énfasis en la frase no estructurados. Esto
significa que dentro de las bases de datos bajo estudio podemos encontrar información
de muy desigual naturaleza (videos, imágenes, sonidos, números, etc). Las técnicas
cuantitativas del Big Data permiten analizar estas masas amorfas de datos y establecer
las características de los patrones que de ellas surgen.
¿Cuán grandes son esas bases de datos? Para valorar su magnitud podemos hacernos la
siguiente pregunta: ¿qué ocurre en un minuto en internet? En la Figura 1 se expone una infografía que brinda alguna información al respecto:
-
Se hacen 701,389 logins en Facebook.
-
Se ven 69,444 horas de video en Netflix.
-
Se envían 150 millones de e-mails.
-
Se comparten 527,760 fotos en Snapchat.
-
Se descargan 51,000 apps del Apple’s App Store.
-
Amazon recauda USD 203,596 en ventas.
-
Se inician más de 120 nuevas cuentas en Linkedin.
-
Se publican 347,222 tweets en Twitter.
-
Se ponen 28,194 nuevas publicaciones en Instagram.
-
Se oyen 38,052 horas de música en Spotify.
-
Se hacen 2.4 millones de busquedas en Google.
-
Se visualizan 2.78 millones de videos en YouTube.
-
Se publican 20.8 millones de mensajes en WhatsApp.
Figura 1
¿Qué ocurre en un minuto en internet?
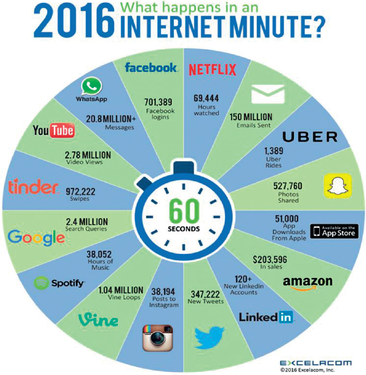
Estos volúmenes de datos eran impensables hacen 10 años. Tal vez lo más llamativo
es la rapidez con la cual están creciendo. La velocidad a la cual se produce innovación
es también notable. Una de las filosofías de gestión más famosas de Google ha sido
la “regla del 20%”. La leyenda dice que, especialmente en los primeros días de Google,
se animó a los empleados a dedicar el 20% de su tiempo a trabajar en nuevas iniciativas
que potencialmente podrían beneficiar a Google fuera de sus flujos de trabajo, equipos
y proyectos regulares. Esto significaba que había tiempo para explorar nuevas ideas
o para desafiar los status quo existentes dentro de la organización.
La Tabla 1 muestra los ingresos brutos y netos de algunas empresas cada 10segundos.
Tabla 1
Ingresos brutos y netos de algunas empresas del sector de las tecnologías de la información
cada 10 segundos.
|
Empresa
|
Ingresos brutos
|
Ingresos netos
|
|
Apple
|
54,190
|
11,740
|
|
Facebook
|
2,490
|
480
|
|
Amazon
|
23,610
|
90
|
|
Google
|
17,610
|
4,090
|
|
Microsoft
|
24,690
|
6,930
|
|
Yahoo
|
1,480
|
430
|
|
Netflix
|
1,390
|
40
|
|
LinkedIn
|
490
|
10
|
|
Dropbox
|
70
|
40
|
|
Twitter
|
210
|
-200
|
Frente a esta realidad, debemos preguntarnos, ¿cómo se transformarán las ciencias
sociales frente a este océano de datos?, ¿de qué forma los conceptos clásicos de esta
área del saber humano pueden ayudar a entender los nuevos fenómenos que se avecinan?
Otro campo donde los métodos del Big Data están dejando huella es en las humanidades.
Al interior de esta amplia área de nuestra cultura, se ha acuñado el término humanidades
digitales11 para designar aquellos proyectos donde las computadoras digitales han obtenido un
papel toral en la viabilidad de los mismos. Es preciso reconocer aquí que la definición
y los objetos de estudio están aún en construcción, pero algunas voces argumentan
en diferentes direcciones, brindando pautas para una definición precisa.
Por ejemplo, en [11] se afirma:
La tecnología informática ha mediado en el desarrollo de métodos formales en el área
de las humanidades. Estos métodos suelen ser mucho más poderosos que la investigación
tradicional con lápiz y papel. Incluyen, por ejemplo, las técnicas de análisis en
lingüística computacional, el cálculo del tiempo expresivo en la música, el uso de
estadísticas exploratorias en la estilística formal, la búsqueda visual en la historia
del arte y la minería de datos en la historia. Aunque el progreso científico es en
primer lugar debido a mejores métodos, en lugar de únicamente debido a mejores computadoras,
los nuevos métodos avanzados confían fuertemente en las computadoras para su validación
y uso efectivo.
No obstante, una característica distintiva de los puntos de vista es el uso de las
computadoras como herramientas y no como protagonistas del proceso de investigación. En esta dirección vale mencionar
la opinión de S. Katz [12]: “Para el humanista tal vez nada es más importante que la capacidad de organizar
y buscar grandes cuerpos de información”.
Así, quedan abiertas regiones, como el análisis semántico de textos y la coherencia
de los mismos, la composición y la generación automática de textos y música, entre
otras muchas.12